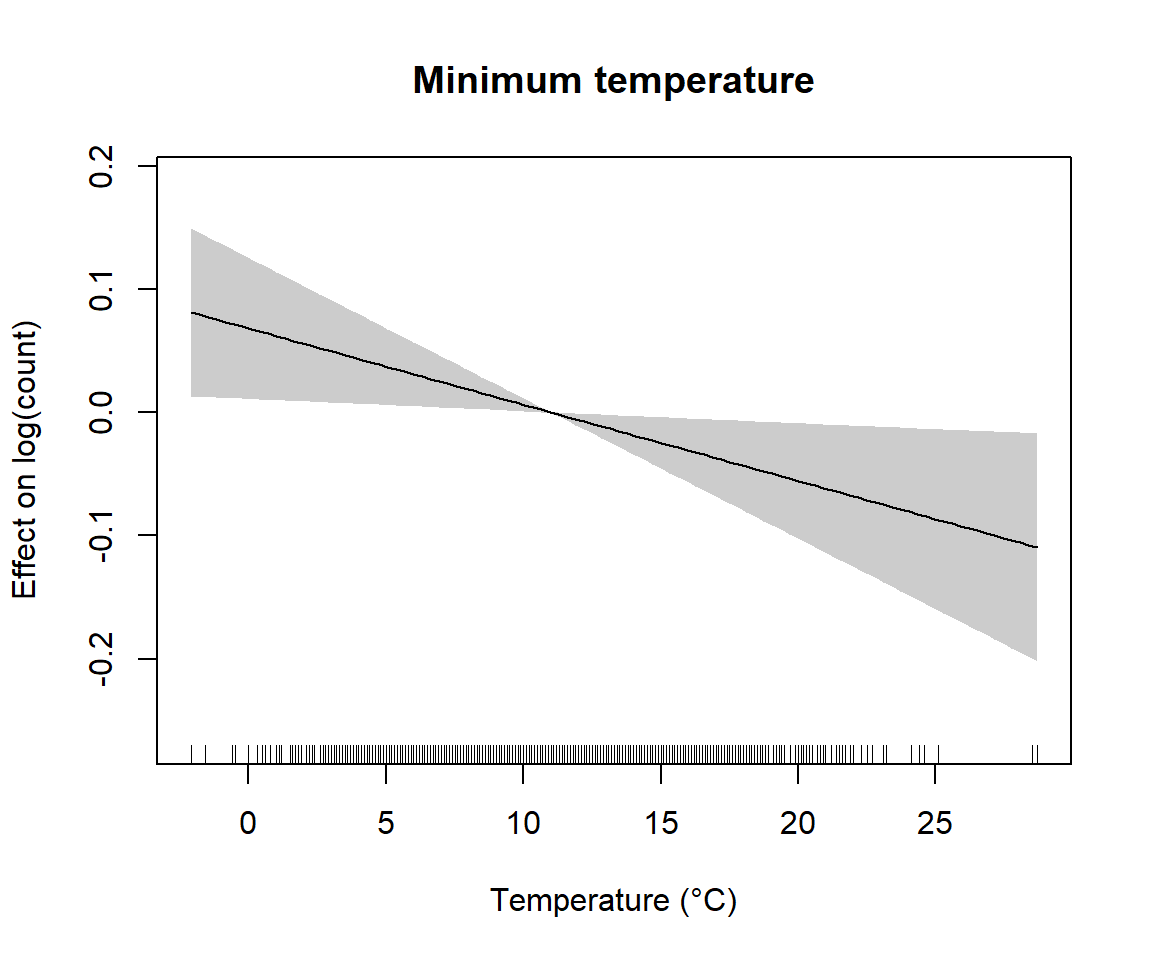
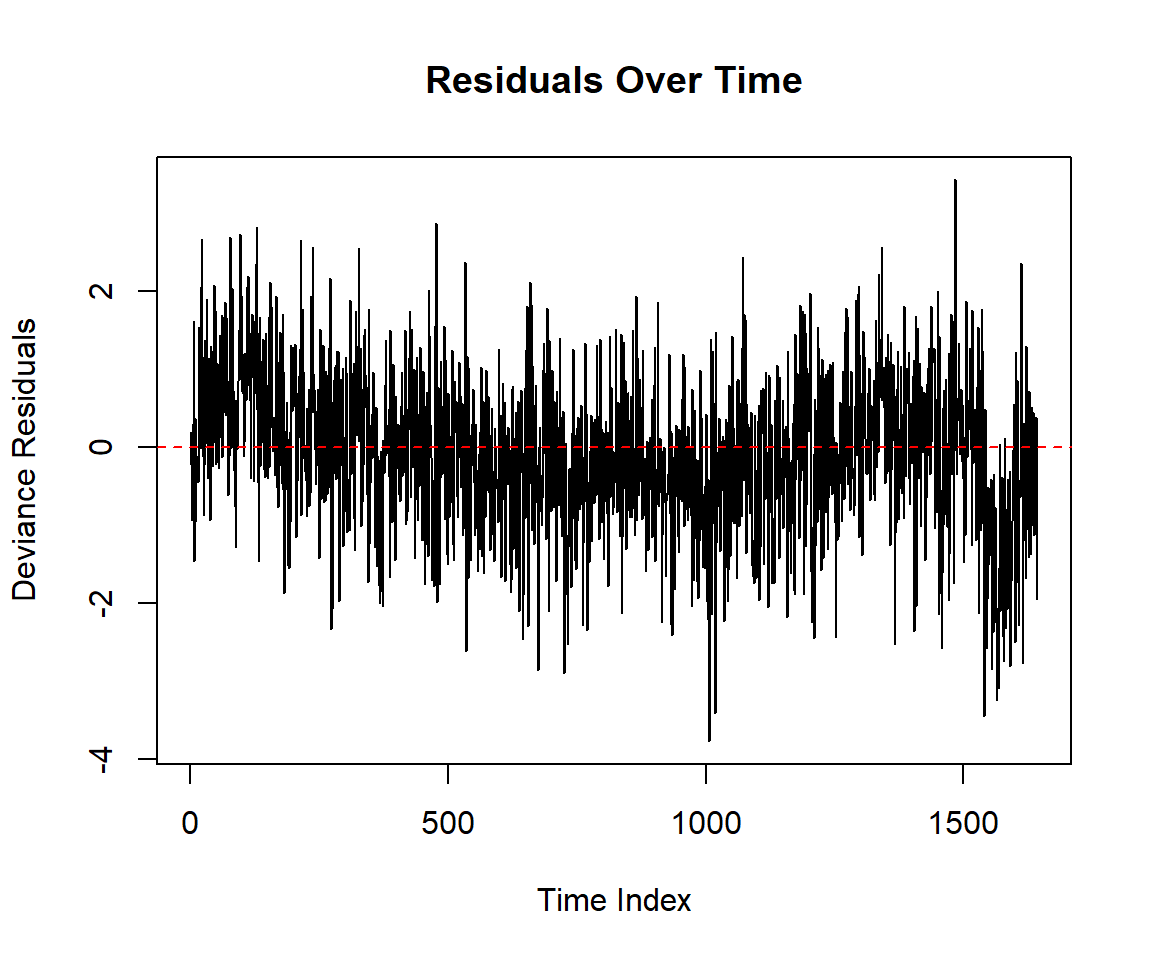
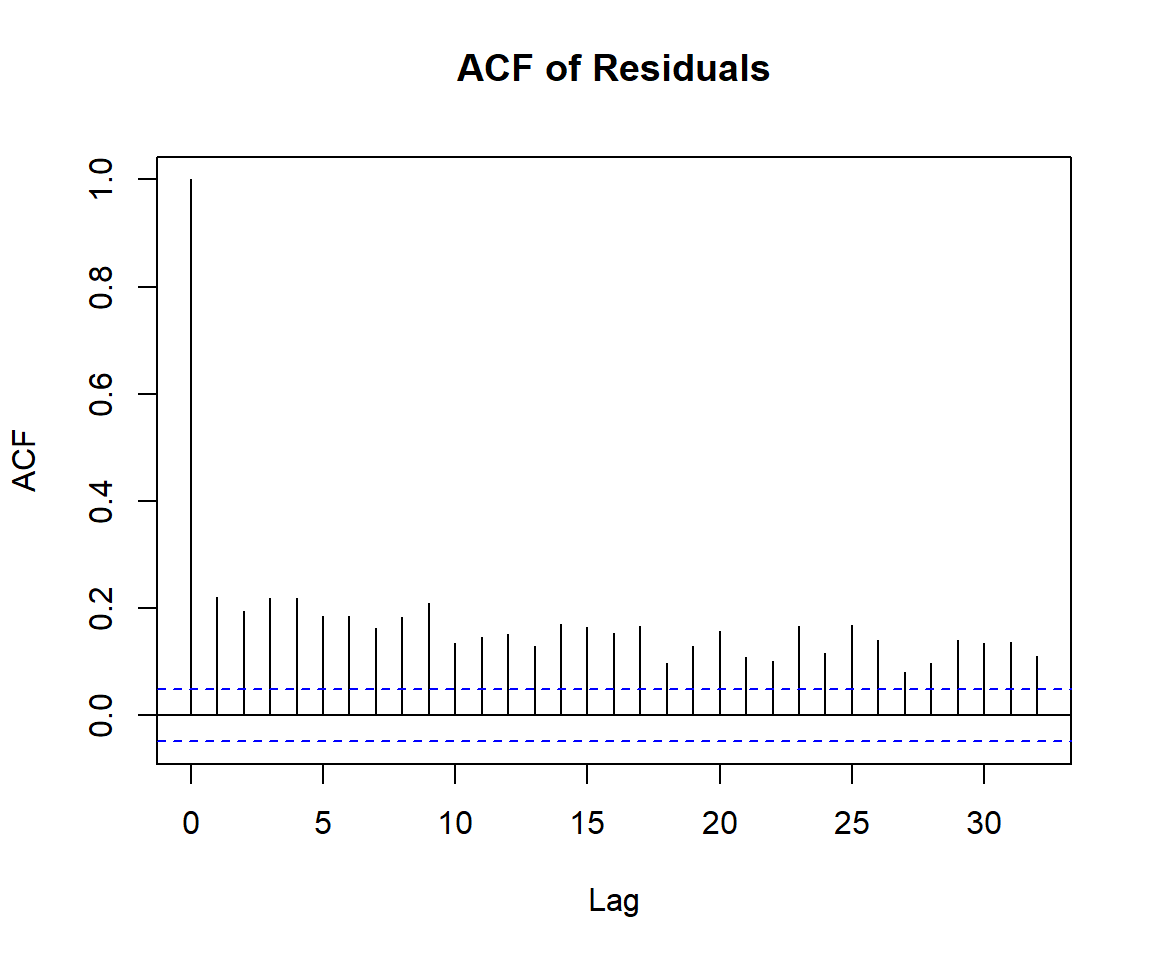
Rows: 1,644
Columns: 29
$ X <chr> "DATE", "1/01/2016", "2/01/2016", "3/01…
$ EASTERN.REGION <chr> "FATAL", "0", "0", "0", "0", "0", "0", …
$ X.1 <chr> "SERIOUS", "1", "3", "1", "2", "1", "2"…
$ X.2 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.3 <chr> "OTHER", "5", "1", "5", "2", "6", "1", …
$ METROPOLITAN.NORTH.WEST.REGION <chr> "FATAL", "0", "0", "0", "0", "1", "0", …
$ X.4 <chr> "SERIOUS", "7", "2", "3", "2", "2", "5"…
$ X.5 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.6 <chr> "OTHER", "7", "4", "6", "5", "7", "13",…
$ METROPOLITAN.SOUTH.EAST.REGION <chr> "FATAL", "1", "0", "0", "0", "0", "0", …
$ X.7 <chr> "SERIOUS", "9", "8", "7", "4", "6", "7"…
$ X.8 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.9 <chr> "OTHER", "3", "5", "4", "5", "7", "8", …
$ NORTH.EASTERN.REGION <chr> "FATAL", "0", "1", "0", "0", "0", "0", …
$ X.10 <chr> "SERIOUS", "3", "2", "2", "1", "6", "0"…
$ X.11 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.12 <chr> "OTHER", "2", "1", "3", "1", "2", "0", …
$ NORTHERN.REGION <chr> "FATAL", "0", "0", "0", "1", "0", "0", …
$ X.13 <chr> "SERIOUS", "1", "2", "0", "4", "0", "3"…
$ X.14 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.15 <chr> "OTHER", "1", "1", "3", "3", "3", "4", …
$ SOUTH.WESTERN.REGION <chr> "FATAL", "0", "0", "0", "0", "0", "0", …
$ X.16 <chr> "SERIOUS", "2", "2", "2", "1", "3", "1"…
$ X.17 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.18 <chr> "OTHER", "0", "2", "1", "3", "1", "3", …
$ WESTERN.REGION <chr> "FATAL", "0", "0", "0", "0", "0", "0", …
$ X.19 <chr> "SERIOUS", "1", "1", "2", "0", "2", "2"…
$ X.20 <chr> "NOINJURY", "0", "0", "0", "0", "0", "0…
$ X.21 <chr> "OTHER", "0", "2", "4", "1", "1", "1", …